
OWASP FSTM, etapa 3: Análisis del firmware
Tabla de contenidos

Analizar un volcado de un firmware no es una tarea sencilla que se pueda resumir en simples pasos para obtener una fórmula válida para todos los casos. A continuación, se revisarán distintas técnicas que pueden ayudar a extraer datos de estos volcados.
Es habitual durante el análisis del firmware enfrentarse a formatos no documentados, soluciones propietarias e incluso datos cifrados. Por este motivo es importante no perder el contexto en el que se realiza el análisis y toda la información recabada en los pasos anteriores. Con este contexto en mente se podrá elegir con criterio entre las distintas herramientas y análisis que se proponen.
A continuación, se propone transformar el formato del volcado de firmware disponible en un formato binario estandarizado para su posterior análisis. También se dedica una sección a aquellos casos en los que nuestro firmware pueda incluir más datos de los deseados, pudiendo alterar los resultados de las pruebas posteriores. Finalmente, se listan métricas, herramientas y técnicas que nos permiten identificar secciones, formatos y firmas dentro de un firmware para poder hacer una extracción posterior.
Obtención de un volcado binario en bruto
Dependiendo de las técnicas usadas en la etapa dos (OWASP FSTM, etapa 2: Obtención del firmware de dispositivos IoT) de esta guía, el volcado del firmware puede encontrarse en distintos formatos. El objetivo de esta sección es convertir ese formato en un formato binario en bruto.
Muchas de las herramientas de análisis disponibles, se basarán en formatos binarios y obtener un binario es una tarea importante en caso de que en algún momento se desee realizar una emulación total del dispositivo.
En este primer paso, se apoya en información previa para saber en qué formato se ha realizado el volcado de firmware. El investigador debe consultar la documentación de la herramienta utilizada para, con certeza, realizar una conversión a formato binario.
A pesar de ello, un editor de texto y un editor hexadecimal deberían ser suficientes para verificar la información de las herramientas utilizadas o para averiguar en que formato se puede encontrar un volcado. A continuación, se resumen los formatos más habituales para este tipo de tareas y sus características generales.
Intel HEX
Siendo uno de los formatos más antiguos para representar el contenido de memorias, se puede caracterizar por su código de inicio de línea, los dos puntos ‘:’. Aunque el formato es más complejo, para los casos sencillos se puede resumir en que por cada línea se suele incluir el código de inicio, una longitud del registro, la dirección del registro, un tipo de registro (datos, normalmente) y un checksum final. Para más detalles sobre el formato se puede consultar el siguiente enlace. Para la obtención de un binario a partir de un archivo de este tipo, se pueden utilizar múltiples herramientas como Intel_Hex2Bin, o SRecord.
:10010000214601360121470136007EFE09D2190140
:100110002146017EB7C20001FF5F16002148011988
:10012000194E79234623965778239EDA3F01B2CAA7
:100130003F0156702B5E712B722B732146013421C7
:00000001FF
SREC o Motorola S-Record
Se trata de un formato muy similar al Intel HEX. De nuevo se define un código de inicio acompañado de distintos campos para describir registros de datos en formato hexadecimal. Puede distinguirse porque en este caso el código de inicio es una ‘S’. Para más información se puede consultar este enlace. Para convertir este formato a binario, se pueden usar las mismas herramientas que en el apartado anterior.
S00F000068656C6C6F202020202000003C
S11F00007C0802A6900100049421FFF07C6C1B787C8C23783C6000003863000026
S11F001C4BFFFFE5398000007D83637880010014382100107C0803A64E800020E9
S111003848656C6C6F20776F726C642E0A0042
S5030003F9
S9030000FC
Hexdump o cadena hexadecimal
Como se ha comentado en el artículo OWASP FSTM, etapa 2: Obtención del firmware de dispositivos IoT, en algunas ocasiones se tendrá acceso a los dispositivos mediante interfaces de texto y con herramientas limitadas. Una de las opciones más comunes en este caso para el volcado de la memoria es hexdump o alguna de sus alternativas. Normalmente un volcado hexadecimal con estas herramientas consiste en una columna de direcciones, una columna con el contenido de la memoria en hexadecimal y finalmente una columna opcional con el contenido codificado en texto. Para restaurar este formato a un binario en bruto una de las herramientas más comunes es xxd con el parámetro ‘ – r’ de revert. Para más información sobre el formato consulta el siguiente enlace.
00000000 30 31 32 33 34 35 36 37 38 39 41 42 43 44 45 46 |0123456789ABCDEF|
00000010 0a 2f 2a 20 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a |./* ************|
00000020 39 2e 34 32 0a |9.42.|
Base64
Al igual que en el caso del hexdump, base64 es un formato útil para la transmisión de un binario codificado por un canal que solo soporta caracteres imprimibles. Aunque es menos común encontrarse una utilidad para generar el base64 de un fichero, muchos lenguajes modernos incluyen bibliotecas para hacerlo.
Si se encuentra un dispositivo empotrado sin la utilidad de línea de comandos para base64, es común poder codificar desde Python, Perl u otros lenguajes en el dispositivo. Base64 define una tabla que permite transformar entre un valor binario y un mapa definido para esta codificación. La ventaja es que esta tabla de valores, en vez de ser de 16 símbolos (hexadecimal) es de 64, permitiendo contener mucha más información por cada carácter transmitido, ahorrando mucho ancho de banda en comunicaciones muy limitadas en velocidad. Debido a que esta codificación incluye más de un byte por símbolo, a veces requiere un padding final que se realiza con el carácter ‘=’, muy característico de esta representación. Para saber más sobre esta codificación puede consultarse el siguiente enlace.
bGlnaHQgd29yaw==
Cribado de los datos de fuera de banda y de paridad
Una vez se tiene un archivo binario es el momento de eliminar los datos de fuera de banda y paridad para obtener sólo la porción exclusivamente útil de la memoria.
Los datos de fuera de banda en memorias flash sirven para almacenar un índice de bloques de la memoria que se encuentran en mal estado para evitar su uso. En esta sección también suele incluirse una reserva de bits para cálculo de paridad de manera que exista un mecanismo de detección de fallos y corrección de los bits que hayan podido producir el error.
Este paso sólo es relevante tras un volcado de memoria mediante técnicas “chip-off”, que consisten en la extracción física de la memoria, puesto que, en estos casos, se extrae todo su contenido, incluyendo secciones utilizadas como redundancia para mejorar la integridad de los datos almacenados.
El caso ejemplo se trata de un volcado de memoria NAND Flash.
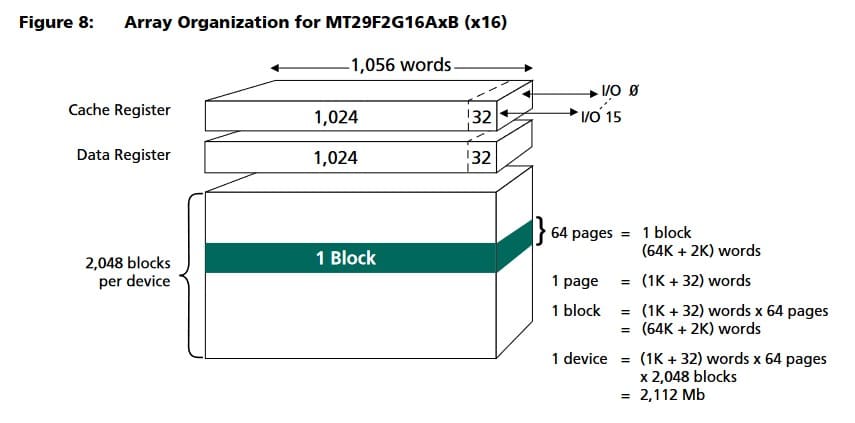
Fuente: Micron
Como se aprecia en la imagen anterior, extraída de la hoja de características de una memoria NAND Flash de Micron, esta memoria se organiza en bloques. Cada uno de los 2.048 bloques tiene un conjunto de 64 páginas. Según la imagen, para esta memoria, cada página tiene de ancho 1.024+32 palabras. Cuando el usuario accede a la memoria, percibe que cada página ocupa un total de 1.024 palabras, aunque en la estructura de la memoria existen 32 palabras adicionales que sirven para la corrección de errores de la memoria.
Esta estructura de ejemplo es bastante común, aunque cada fabricante puede elegir distintos tamaños para estas estructuras de redundancia o incluso otras disposiciones donde la memoria redundante se encuentre en bloques al final de la memoria en lugar de estar intercalada dentro de cada bloque o página.
Para el análisis y la eliminación de los datos redundantes en un volcado existen soluciones que intentan automatizar el proceso como https://github.com/Hitsxx/NandTool, aunque en ocasiones se tendrá que realizar un análisis manual mediante el estudio de la entropía del archivo e, incluso, técnicas de autocorrelación.
Una vez se ha obtenido un archivo en formato binario sin datos de redundancia o “out of bands”, se inicia el proceso de análisis de los contenidos del firmware.
Análisis de entropía
La entropía computacional es un concepto de la teoría de la información, desarrollada principalmente por C. E. Shannon, que trata de obtener una medida de la incertidumbre de los posibles valores que puede tomar una variable aleatoria. Para un conjunto de datos de origen y formato indeterminado, se ha reinterpretado este concepto para tratar de obtener una medida de la aleatoriedad de los valores que contiene.
Debido al cambio de contexto en el que se aplica el concepto de entropía, los resultados del cálculo para un conjunto de datos de estructura indeterminada se aproximan más a una medida de cuánto varían los bytes de la muestra.
Partiendo de esta definición, a continuación, se muestra la utilidad del concepto en el estudio de una imagen de firmware.
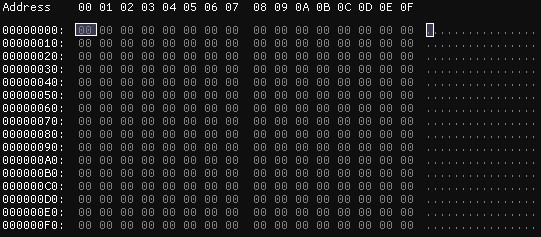
Utilizando un (supuesto) generador aleatorio, se genera un archivo de 256 bytes como el que se muestra en nuestra imagen (todos los números generados son 0). Como no existe aleatoriedad en los valores, la entropía total del archivo es 0.
Utilizando la segunda definición, puede entenderse que, al no haber variación entre los bytes, el cálculo de la entropía es 0.
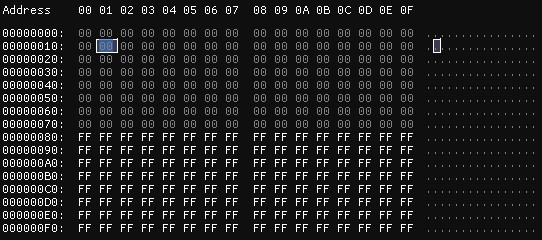
Suponiendo que el programador ha “corregido” el generador aleatorio usado en el ejemplo anterior, se vuelcan otros 256 bytes de información en un archivo, esta vez el resultado es que la mitad del archivo contiene el valor 00 y la otra mitad contiene el valor FF. En este caso, el archivo contiene más “aleatoriedad” que, en el caso anterior, por lo que se espera un incremento en esta medida. Para verificarlo se ejecuta binwalk en modo de cálculo de entropía y se obtiene un resultado mayor que en el caso anterior, 0,125.
% binwalk -E halfceros.bin
DECIMAL HEXADECIMAL ENTROPY
——————————————————————————–
0 0x0 Falling entropy edge (0.125000)
Ha de tenerse en cuenta que algunas de estas herramientas “normalizan” el valor de la entropía calculada. Algunas herramientas arrojarán un valor de 1 punto de entropía sobre un máximo de 8, mientras que otras mostrarán un valor de 0,125 sobre un máximo de 1.
También se podría decir que los bytes de este archivo varían algo más entre sí que en el caso anterior.
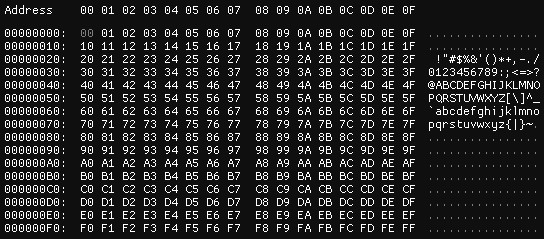
Continuando con el ejemplo anterior, si el generador aleatorio ahora escribe todos los valores posibles de un byte secuencialmente en nuestro archivo, la entropía se dispara a su máximo. Si la fuente de información es aleatoria, esa fuente de información es capaz de usar todos los bytes posibles por lo que su “aleatoriedad” es alta.
% binwalk -E fullent.bin
DECIMAL HEXADECIMAL ENTROPY
——————————————————————————–
0 0x0 Rising entropy edge (1.000000)
Este es un claro ejemplo de tomar la entropía como una medida precisa de la aleatoriedad es un error. En este caso, la aleatoriedad del contenido es baja y se podría predecir el siguiente valor simplemente sumando una unidad al valor anterior. En este caso, debe entenderse es que los bytes tienen la máxima variación posible, ya que cada uno toma un valor diferente a los anteriores.
Un ejemplo más mundano de esto se podría dar con nuestro lenguaje. Tomando como símbolo una palabra en lugar de un byte, si se analiza la entropía de una obra literaria se obtendría un valor de entropía desconocido X.
Si en esta misma obra se eliminasen todos los pronombres, probablemente seguiríamos pudiendo comprenderla en su totalidad. Los pronombres, a la par que frecuentes, dentro de la obra literaria aportan poca información. Si ahora se realizase un cálculo de la entropía de la obra sin los pronombres nos encontraríamos con una medida Y mayor a la del caso anterior (Y>X).
Lo que nos revela esto es que cada palabra en la segunda obra aporta más información de media que en la primera a pesar de que en ninguno de los dos casos la elección de las palabras ha sido totalmente aleatoria.
Para ampliar este concepto se recomienda la lectura del artículo de Wikipedia.
En el caso del análisis del firmware, el análisis de entropía puede ayudar a identificar firmas y dar indicios de distintos orígenes de datos.
Dado que los datos que analizándose analizan no son totalmente aleatorios, se puede aprovechar el análisis de entropía como un medio para poder identificar distintos orígenes de estos datos.
Si se calcula la entropía del fichero de firmware de nuestro dispositivo en ventanas móviles, se obtendrá una medida continua de la entropía del archivo que se puede representar gráficamente. Esta gráfica puede ser continua o tener una alta varianza y esto puede indicarnos que los datos que se observan pueden proceder de distintos algoritmos o tener distintos usos.
Para ejemplificar esto se realiza un análisis sobre la imagen “IoT Goat v1.0” de OWASP. Se trata de una imagen deliberadamente vulnerable para el estudio de estas técnicas y se puede encontrar en este enlace.
Sobre la imagen de este firmware, se hace un cálculo de la entropía:
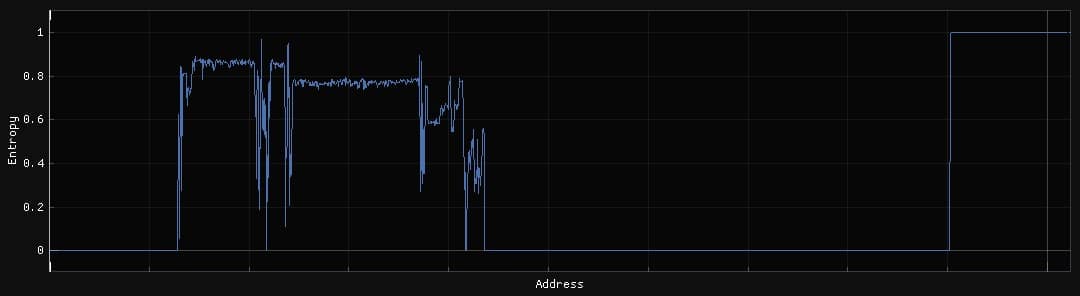
De esta imagen se puede extraer que posiblemente existan diversas secciones con diversos usos en este firmware. Parece haber una sección inicial que no tiene contenido seguida de una sección con una entropía relativamente alta. En medio existen partes con diversos picos que habría que analizar en mayor detalle, pero seguidamente se encuentra otra sección plana con otro nivel de entropía menor a la primera. Esto podría parecer otro tipo de archivo, formato o partición del firmware.
Después de esta posible sección se encuentra otra zona turbulenta y poco clara, seguida de un gran valle que parece no tener uso y finalmente una zona de entropía muy elevada que posiblemente se trate de una tercera sección.
Los puntos donde se producen estas variaciones de entropía son puntos de estudio importantes. En ellos posiblemente se puedan encontrar firmas de formatos o algoritmos usados para generarlas.
Además de la información que aporta la variación en la entropía, su valor en sí mismo nos permite hacer suposiciones sobre el estado en el que se encuentran los datos.
En secciones donde se encuentren valores altos de entropía será posiblemente debido al uso de algoritmos de compresión o cifrado de datos. Como regla general, los procesos de compresión generan los valores más altos de entropía, ya que intentan empaquetar la mayor cantidad de información posible por byte, mientras que los procesos de cifrado, que buscan maximizar la aleatoriedad del resultado, suelen situarse justo por debajo de la compresión. Esto puede no ser así para todos los algoritmos de compresión y cifrado.
Identificación de firmas
Muchos formatos de archivo y sistemas de ficheros utilizan una serie de bytes como identificador, que habitualmente se denominan “magic numbers” o firmas. Durante el análisis del firmware es de gran utilidad identificar firmas de tipos de archivos conocidos, para lo cual existen múltiples herramientas.
La herramienta automática más utilizada en el estudio de firmware es binwalk. Esta cuenta con funciones de identificación de archivos en el firmware, tanto mediante la búsqueda de firmas como detectando la codificación de una sección y buscando patrones. El uso básico de binwalk es mediante el terminal:
$ binwalk IoTGoat-raspberry-pi2.img
DECIMAL HEXADECIMAL DESCRIPTION
——————————————————————————–
4253711 0x40E80F Copyright string: «copyright does *not* cover user programs that use kernel»
…
4329472 0x421000 ELF, 32-bit LSB executable, version 1 (SYSV)
4762160 0x48AA30 AES Inverse S-Box
4763488 0x48AF60 AES S-Box
5300076 0x50DF6C GIF image data, version «87a», 18759
5300084 0x50DF74 GIF image data, version «89a», 26983
…
6703400 0x664928 Ubiquiti firmware additional data, name: UTE_NONE, size: 1124091461 bytes, size2: 1344296545 bytes, CRC32: 0
…
6816792 0x680418 CRC32 polynomial table, little endian
6820888 0x681418 CRC32 polynomial table, big endian
6843344 0x686BD0 Flattened device tree, size: 48418 bytes, version: 17
6995236 0x6ABD24 GIF image data, version «89a», 28790
…
12061548 0xB80B6C gzip compressed data, maximum compression, from Unix, last modified: 1970-01-01 00:00:00 (null date)
12145600 0xB953C0 CRC32 polynomial table, little endian
12852694 0xC41DD6 xz compressed data
12880610 0xC48AE2 Unix path: /dev/vc/0
…
14120994 0xD77822 Unix path: /etc/modprobe.d/raspi-blacklist.conf can
…
29360128 0x1C00000 Squashfs filesystem, little endian, version 4.0, compression:xz, size: 3946402 bytes, 1333 inodes, blocksize: 262144 bytes, created: 2019-01-30 12:21:02
En el ejemplo se puede comprobar que binwalk ha detectado cadenas de texto, referencias a ubicaciones del sistema, ejecutables en formato ELF, estructuras de datos pertenecientes al algoritmo de cifrado AES, imágenes, códigos CRC, árboles de dispositivos, archivos comprimidos y sistemas de ficheros.
A pesar de la rapidez y sencillez del uso de binwalk, debido al tipo de análisis que realiza, basado en heurísticos, son frecuentes los falsos positivos. Siempre es conveniente revisar manualmente, con un editor hexadecimal, las direcciones de memoria que binwalk indica en sus resultados, especialmente si los resultados no coinciden con hallazgos anteriores.
Una herramienta complementaria a binwalk es fdisk. Especialmente cuando se trabaja con archivos de gran tamaño, binwalk puede ser lenta. Además, fdisk es una herramienta que nos permite identificar particiones en un archivo. La detección de particiones es una de las mejores maneras de partir un firmware en archivos más pequeños y manejables como se describirá más adelante.
Fdisk se trata de una utilidad comúnmente utilizada en Linux que permite el listado y manipulación de tablas de particiones. Si nuestro firmware está particionado se podrá ver con esta utilidad:
$ fdisk -l IoTGoat-raspberry-pi2.img
Disk IoTGoat-raspberry-pi2.img: 31.76 MiB, 33306112 bytes, 65051 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x5452574fDevice Boot Start End Sectors Size Id Type
IoTGoat-raspberry-pi2.img1 * 8192 49151 40960 20M c W95 FAT32 (LBA)
IoTGoat-raspberry-pi2.img2 57344 581631 524288 256M 83 Linux
Otra utilidad que nos permite entender los contenidos de una imagen de firmware es la utilidad file.
$ file hola.txt
hola.txt: ASCII text
Para ello, file ejecuta tres tipos de pruebas diferentes sobre el archivo: búsqueda de información con la llamada al sistema stat, búsqueda de firmas o “magic numbers” e identificación del lenguaje. La llamada al sistema stat obtiene información sobre un archivo disponible en el sistema de ficheros que lo contiene. Por otro lado, file busca posibles firmas sólo en los primeros bytes de un fichero. Por último, file trata de averiguar si se trata de un fichero de texto y la codificación que utiliza, para luego identificar si se trata de algún lenguaje formal conocido, como XML, HTML, C o Java.
Cuando se aplica el comando file sobre el firmware de pruebas de IoT Goat, se obtienen resultados coherentes con los vistos en fdisk:
$ file IoTGoat-raspberry-pi2.img
IoTGoat-raspberry-pi2.img: DOS/MBR boot sector; partition 1 : ID=0xc, active, start-CHS (0x20,2,3), end-CHS (0xc3,0,12), startsector 8192, 40960 sectors; partition 2 : ID=0x83, start-CHS (0xe3,2,15), end-CHS (0x14,0,16), startsector 57344, 524288 sectors
Aquí, file detecta una tabla de particiones de DOS/MBR con dos particiones. En este caso, file detecta la firma que se encuentra en el inicio de la imagen, e ignora el resto de los contenidos. Por ello, al encontrar un resultado como el anterior conviene inspeccionar el fichero con más detalle.
Por otro lado, en otros casos en los que el firmware ha sido extraído directamente desde la memoria del dispositivo, file puede mostrar un resultado similar a el siguiente:
$ file firmware.bin
firmware.bin: data
Este resultado indica que file no es capaz de identificar el formato del archivo, lo que se debe a que es un archivo “binario” (sin estructura determinada) y las posibles firmas y números mágicos que contiene no se encuentran al inicio.
También es posible buscar manualmente firmas de archivo conocidas utilizando un editor hexadecimal:

Una lista de las firmas de fichero más conocidas puede encontrarse en este enlace.
Seccionado del binario
Teniendo identificada una sección de la imagen de firmware, esta se puede analizar como un archivo independiente extrayéndolo con herramientas como dd. La herramienta dd simplemente copia bytes de un archivo de entrada hacia un archivo de salida. Es una de las herramientas clásicas de los sistemas Linux y cuenta con muchas opciones de configuración.
En algunos casos, ya se habrán encontrado los límites de una sección, pero, en otros, será necesario definir dónde termina un archivo. Para extraer, por ejemplo, el ejecutable ELF detectado por binwalk en la dirección 0x421000, primero es necesario determinar su tamaño leyendo la cabecera ELF en la dirección de inicio del archivo.
Binwalk tiene la capacidad de hacer este seccionado y extraer los datos, pero no siempre da buenos resultados, ya que para muchos formatos no calcula los tamaños totales de los archivos y simplemente hace una copia desde una firma hasta el final del firmware, obteniendo mejores resultados si el trabajo se realiza manualmente.
Este proceso de seccionado puede ser importante para poder partir firmwares demasiado grandes en trozos más manejables para su posterior procesado o extracción.
Distribución de bytes
Otro análisis que puede revelar que uso puede tener un archivo es un histograma que represente la distribución de los valores en el archivo.
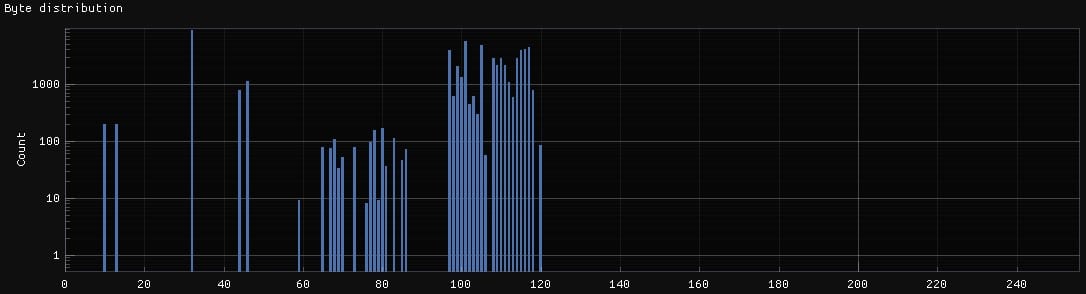
Para el histograma anterior se puede ver un extendido uso de bytes con valores desde el 97 hasta el 120. En menor medida existe también un uso de bytes en el rango 41 a 86. Existe un pico aislado con el valor 32 y dos picos de menor medida en los valores 10 y 13.
Este perfil mostrado coincide con las distribuciones de caracteres usables en la tabla ASCII. En especial, el pico en el carácter 32 correspondiente al carácter que representa un espacio en blanco, el carácter estadísticamente más usado en el texto plano.
Mediante el perfilado de la distribución de bytes de un archivo pueden llegar a reconocerse distintas codificaciones de archivo e incluso estimar los posibles idiomas en los que está escrito ese texto.
Estas mismas caracterizaciones pueden darse en archivos binarios o algoritmos ya que dependiendo de su uso muestran un sesgo en la distribución por las distintas maneras de codificar la información.
Búsqueda de cadenas
Aunque se trate de uno de los análisis más básicos que se pueden realizar, listar las cadenas de texto que hay dentro de un archivo o un firmware pueden aportar mucha información a la hora de realizar un análisis.
En el caso de archivos binarios, strings puede mostrar mensajes de depuración, licencias de software, mensajes de versión o incluso nombres de funciones a las que se llama desde un binario. Saber qué software puede estar ejecutando un binario aporta mucha información al contexto en el que se está realizando el análisis.
Es común también encontrar strings con fechas de compilación o empaquetado de firmwares, que puede aportar información de como de actualizado o desactualizado se encuentra el firmware.
$ strings IoTGoat-raspberry-pi2.img
…
console=ttyAMA0,115200 kgdboc=ttyAMA0,115200 console=tty1 root=/dev/mmcblk0p2 rootfstype=ext4 rootwait
…
squashfs: version 4.0 (2009/01/31) Phillip Lougher
…
DTOKLinux version 4.9.152 (embedos@embedos) (gcc version 7.3.0 (OpenWrt GCC 7.3.0 r7676-cddd7b4c77) ) #0 SMP Wed Jan 30 12:21:02 2019
…
En ocasiones el comando strings puede devolver demasiada información, por lo que se proporciona el parámetro ‘-n’ para poder establecer longitudes mínimas en las cadenas que devuelve.
Búsqueda de otras constantes
En ocasiones se identifican secciones cifradas mediante el uso de análisis de entropía, la distribución de bytes u otros medios. Identificada una sección así, no existen muchas opciones para discernir si realmente esa sección está comprimida o cifrada cuando no se encuentren firmas en ellas.
En estos casos es interesante buscar constantes en estas y otras secciones colindantes que nos puedan orientar a la hora de hacer esta identificación. Muchos algoritmos criptográficos hacen uso de estructuras constantes para definir su estado inicial. Otras, se calculan comúnmente en base a tablas.
Es común encontrar los vectores de inicialización de distintos algoritmos de hashing como MD5, SHA1, SHA256… También es frecuente encontrar tablas que implementan las “Rijndael S-Box” o “AES S-Box” que indican el uso del algoritmo AES, o tablas para el cálculo de códigos CRC, de detección y corrección de errores.
Tener esta información, además, ayuda a hacer análisis manualmente mediante editores hexadecimales, ya que indica qué medios de comprobación de integridad se han usado para construir la imagen del firmware. Así, si se encuentra un campo desconocido en un formato propietario y se han detectado firmas de algoritmos CRC, es interesante comprobar los algoritmos CRC más comunes como una alternativa para el contenido de ese campo.
Análisis manual con un editor hexadecimal
El editor hexadecimal es una herramienta fundamental para el análisis del firmware. Aunque existan muchas herramientas que permiten automatizar este proceso, todas o muchas de ellas se basan en heurísticos y requerirán una supervisión manual.
Es importante que se evalúen las múltiples alternativas de este tipo de software para encontrar una con la que el investigador se sienta cómodo ya que esa inversión de tiempo será rentable en el corto plazo.
Distintas alternativas ofrecen distintas funcionalidades que pueden ser de gran utilidad: soporte para poner marcadores en un archivo, reconocimiento de estructuras, análisis de entropía, distintos motores de búsqueda, calculadoras de CRC, hashes…
Tan importante es esta herramienta como el tiempo que se destina a su uso. La inversión de tiempo haciendo estas verificaciones manualmente puede aportar grandes beneficios ya que la experiencia permite reconocer patrones que muchas de las herramientas automáticas no pueden intuir; una habilidad importante que permite reconocer pequeñas modificaciones sobre algoritmos conocidos como medio de ofuscación.
Como consecuencia de la complejidad que entraña el análisis del firmware, no es sencillo estandarizar un único procedimiento válido para todos los dispositivos. Por ello, será necesario adaptar el flujo de trabajo a cada dispositivo y dependerá mucho del fabricante del mismo.
En un análisis, el investigador tendrá que recurrir a muchas de estas técnicas en muy distintos momentos, priorizando la experiencia y el contexto adquirido durante las primeras etapas del análisis para realmente ser efectivo en esta tarea.
La experiencia y la capacidad para identificar los puntos en los que centrar la atención en cada momento serán importantes durante esta fase para realizar un análisis con efectividad.
Referencias:
- https://es.wikipedia.org/wiki/HEX_(Intel)
- https://es.wikipedia.org/wiki/SREC
- https://en.wikipedia.org/wiki/Hex_dump
- https://en.wikipedia.org/wiki/Base64
- https://hex2bin.sourceforge.net/
- https://srecord.sourceforge.net/
- https://www.micron.com/-/media/client/global/documents/products/data-sheet/nand-flash/20-series/2gb_nand_m29b.pdf
- https://github.com/Hitsxx/NandTool
- https://www.filesignatures.net
- https://es.wikipedia.org/wiki/Entrop%C3%ADa_(informaci%C3%B3n)
- https://github.com/OWASP/IoTGoat
Este artículo forma parte de una serie de articulos sobre OWASP
- Metodología OWASP, el faro que ilumina los cíber riesgos
- OWASP: Top 10 de vulnerabilidades en aplicaciones web
- Análisis de seguridad en IoT y embebidos siguiendo OWASP
- OWASP FSTM, etapa 1: Reconocimiento y búsqueda de información
- OWASP FSTM, etapa 2: Obtención del firmware de dispositivos IoT
- OWASP FSTM, etapa 3: Análisis del firmware
- OWASP FSTM, etapa 4: Extracción del sistema de ficheros
- OWASP FSTM, etapa 5: Análisis del sistema de ficheros
- OWASP FSTM etapa 6: emulación del firmware
- OWASP FSTM, etapa 7: Análisis dinámico
- OWASP FSTM, etapa 8: Análisis en tiempo de ejecución
- OWASP FSTM, Etapa 9: Explotación de ejecutables
- Análisis de seguridad IOT con OWASP FSTM
- OWASP SAMM: Evaluar y mejorar la seguridad del software empresarial
- OWASP: Top 10 de riesgos en aplicaciones móviles